WikiDer > Верность визуальной информации
Эта статья поднимает множество проблем. Пожалуйста помоги Улучши это или обсудите эти вопросы на страница обсуждения. (Узнайте, как и когда удалить эти сообщения-шаблоны) (Узнайте, как и когда удалить этот шаблон сообщения)
|
Верность визуальной информации (VIF) - это полная ссылка оценка качества изображения индекс на основе статистика природных сцен и понятие информации об изображении, извлеченной зрительная система человека.[1] Его разработали Хамид Р Шейх и Алан Бовик в Лаборатории изображения и видеоинженерии (LIVE) на Техасский университет в Остине в 2006 году, и было показано, что он очень хорошо коррелирует с человеческими суждениями о визуальном качестве. Он развернут в ядре Netflix VMAF система мониторинга качества видео, которая контролирует качество изображения всех закодированных видео, транслируемых Netflix. На это приходится около 35% всего потребления полосы пропускания в США и растущий объем потокового видео во всем мире.[2]
Обзор модели
Изображения и видео трехмерной визуальной среды происходят из общего класса: класса естественных сцен. Природные сцены образуют крошечное подпространство в пространстве всех возможных сигналов, и исследователи разработали сложные модели для характеристики этой статистики. Самый реальный мир искажение процессы нарушают эту статистику и делают изображение или видеосигналы неестественными. В индексе VIF используются естественная сцена статистическая (NSS) модели в сочетании с моделью искажения (канала) для количественной оценки информации, совместно используемой между тестовым и эталонным изображениями. Кроме того, индекс VIF основан на гипотезе о том, что эта совместно используемая информация является аспектом верности, который хорошо соотносится с визуальным качеством. В отличие от предшествующих подходов, основанных на чувствительности к ошибкам зрительной системы человека (HVS) и измерении структуры,[3] этот статистический подход используется в теоретико-информационный дает полный справочный (FR) метод оценки качества (QA), который не полагается ни на HVS, ни на параметры просмотра геометрии, ни на какие-либо константы, требующие оптимизации, и при этом конкурирует с современными методами контроля качества.[4]
В частности, эталонное изображение моделируется как результат стохастического "естественного" источника, который проходит через канал HVS и позже обрабатывается мозгом. Информационное содержание эталонного изображения количественно определяется как взаимная информация между входом и выходом канала HVS. Это информация, которую мозг мог бы в идеале извлечь из выходных данных HVS. Затем та же мера определяется количественно в присутствии канала искажения изображения, который искажает выходной сигнал естественного источника до того, как он проходит через канал HVS, тем самым измеряя информацию, которую мозг мог бы в идеале извлечь из тестового изображения. Это показано наглядно на рисунке 1. Затем две меры информации объединяются для формирования меры достоверности визуальной информации, которая связывает визуальное качество с относительной информацией изображения.
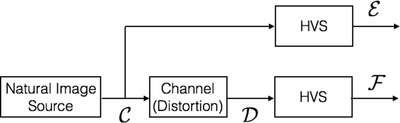
Системная модель
Эта секция не цитировать любой источники. (Январь 2018) (Узнайте, как и когда удалить этот шаблон сообщения) |
Эта статья может быть слишком техническим для большинства читателей, чтобы понять. Пожалуйста помогите улучшить это к сделать понятным для неспециалистов, не снимая технических деталей. (Январь 2018) (Узнайте, как и когда удалить этот шаблон сообщения) |
Исходная модель
Смесь в масштабе Гаусса (GSM) используется для статистического моделирования вейвлет-коэффициенты управляемой пирамидальной декомпозиции изображения.[5] Модель описана ниже для данного поддиапазона многомасштабного многоориентационного разложения и может быть расширена на другие поддиапазоны аналогичным образом. Пусть вейвлет-коэффициенты в данном поддиапазоне равны куда обозначает набор пространственных индексов по поддиапазону, и каждый является размерный вектор. Поддиапазон разделен на неперекрывающиеся блоки коэффициентов каждый, где каждый блок соответствует . Согласно модели GSM,










Модель искажения
Процесс искажения моделируется с использованием комбинации затухания сигнала и аддитивного шума в вейвлет-области. Математически, если обозначает случайное поле из данного поддиапазона искаженного изображения, является детерминированным скалярным полем и , куда гауссов вектор с нулевым средним и ковариацией , тогда






Дальше, моделируется, чтобы быть независимым от и .

Модель HVS
Двойственность моделей HVS и NSS подразумевает, что некоторые аспекты HVS уже учтены в исходной модели. Здесь HVS дополнительно моделируется на основе гипотезы о том, что неопределенность в восприятии визуальных сигналов ограничивает количество информации, которая может быть извлечена из исходного и искаженного изображения. Этот источник неопределенности можно смоделировать как визуальный шум в модели HVS. В частности, шум HVS в данном поддиапазоне вейвлет-разложения моделируется как аддитивный белый гауссов шум. Позволять и случайные поля, где и - гауссовы векторы с нулевым средним и ковариацией и . Далее, пусть и обозначают визуальный сигнал на выходе HVS. Математически мы имеем и . Обратите внимание, что и случайные поля, не зависящие от , и .












Индекс VIF
Эта секция не цитировать любой источники. (Январь 2018) (Узнайте, как и когда удалить этот шаблон сообщения) |
Эта статья может быть слишком техническим для большинства читателей, чтобы понять. Пожалуйста помогите улучшить это к сделать понятным для неспециалистов, не снимая технических деталей. (Январь 2018) (Узнайте, как и когда удалить этот шаблон сообщения) |
Позволять обозначают вектор всех блоков из данного поддиапазона. Позволять и быть определенным аналогично. Позволять обозначают оценку максимального правдоподобия данный и . Объем информации, извлеченной из справки, получается как












Спектакль
Коэффициент корреляции порядка рангов Спирмена (SROCC) между оценками индекса VIF искаженных изображений в базе данных оценки качества изображений LIVE и соответствующими оценками человеческого мнения составляет 0,96.[6]Это говорит о том, что индекс очень хорошо коррелирует с человеческим восприятием качества изображения наравне с лучшими алгоритмами FR IQA.[7]
Рекомендации
- ^ Шейх, Хамид; Бовик, Алан (2006). «Информация об изображении и визуальное качество». IEEE Transactions по обработке изображений. 15 (2): 430–444. Bibcode:2006ITIP ... 15..430S. Дои:10.1109 / tip.2005.859378. PMID 16479813.
- ^ https://variety.com/2015/digital/news/netflix-bandwidth-usage-internet-traffic-1201507187/
- ^ Ван, Чжоу; Бовик, Алан; Шейх, Хамид; Симончелли, Ээро (2004). «Оценка качества изображения: от видимости ошибок до структурного сходства». IEEE Transactions по обработке изображений. 13 (4): 600–612. Bibcode:2004ITIP ... 13..600 Вт. Дои:10.1109 / tip.2003.819861. PMID 15376593. S2CID 207761262.
- ^ http://videoclarity.com/wp-content/uploads/2013/05/Statistic-of-Full-Reference-UT.pdf
- ^ Симончелли, Ээро; Фриман, Уильям (1995). «Управляемая пирамида: гибкая архитектура для многомасштабных вычислений производных». IEEE Int. Конференция по обработке изображений. 3: 444–447. Дои:10.1109 / ICIP.1995.537667. ISBN 0-7803-3122-2. S2CID 1099364.
- ^ http://videoclarity.com/wp-content/uploads/2013/05/Statistic-of-Full-Reference-UT.pdf
- ^ http://videoclarity.com/wp-content/uploads/2013/05/Statistic-of-Full-Reference-UT.pdf
внешняя ссылка
- Лаборатория имидж- и видеотехники в Техасском университете
- Реализация индекса VIF
- База данных оценки качества изображений LIVE